All the Transformer Math You Need to Know | How To Scale Your Model
Source: github.io
#TransformerModels #DeepLearning #NeuralNetworks #AI
All the Transformer Math You Need to Know
Part 4 of How To Scale Your Model (Part 3: Sharding | Part 5: Training)
Here we'll do a quick review of the Transformer architecture, specifically how to calculate FLOPs, bytes, and other quantities of interest.
Counting Dots
Let’s start with vectors
- A dot product of
requires adds and multiplies, or floating-point operations total. - A matrix-vector product
does dot-products along the rows of , for FLOPs. - A matrix-matrix product
does matrix-vector products for each column of , for FLOPs total. - In general, if we have two higher dimensional arrays
and , where some dimensions are CONTRACTING and some are BATCHING. (e.g. ) then the FLOPs cost of this contraction is two times the product of all of the and dimensions where the batch and contraction dimensions are only counted once, (e.g. ). Note that a dimension is only batching if it occurs in both multiplicands. (Note also that the factor of 2 won’t apply if there are no contracting dimensions and this is just an elementwise product.)
Make note of the fact that for a matrix-matrix multiply, the compute scales cubically
Forward and reverse FLOPs
During training, we don’t particularly care about the result of a given matrix multiply; we really care about its derivative. That means we do significantly more FLOPs during backpropagation.
If we imagine B is just one matrix in a larger network and A are our input activations with C = A B, the derivative of the loss L with respect to B is given by the chain rule:
which is an outer product and requires 2NPM FLOPs to compute (since it contracts over the N dimension). Likewise, the derivative of the loss with respect to A is
is again 2NPM FLOPs since dL/dC is a (co-)vector of size
Adding these up, we see that during training, we have a total of 6NPM FLOPs, compared to 2NPM during inference: 2NPM in the forward pass, 4NPM in the backward pass. Since PM is the number of parameters in the matrix, this is the simplest form of the famous
Transformer Accounting
Transformers are the future. Well, they’re the present at least. Maybe a few years ago, they were one of many architectures. But today, it’s worth knowing pretty much every detail of the architecture. We won’t reintroduce the architecture but this blog and the original Transformer paper may be helpful references.
Here’s a basic diagram of the Transformer decoder architecture:
![]()
Figure: this diagram shows one layer of a standard Transformer and flows from top-to-bottom. We use a single-letter convention to describe the shapes and layouts of arrays in a Transformer, again showing contracting dimensions in red, and batched dimensions in blue. In a given operation, the input shape is given on top-left and the parameter shape is given on the top-right, with the resulting shape below, e.g. BTD is the input shape for the gating einsum and DF is the weight shape.
Note [gating einsum]: The diagram above uses a “ gating einsums ” where we split the up-projection matrix into two matrices (W_\text{In1} and W_\text{In2} above) whose outputs are elementwise multiplied as a kind of “gating function”. Not all LLMs use this, so you will sometimes see a single W_\text{In} matrix and a total MLP parameter count of 2DF instead of 3DF. Typically in this case, D and F will be scaled up to keep the parameter count the same as the 3 matrix case. With that said, some form of gating einsum is used by LLAMA, DeepSeek, and many other models.
Note 2 [MHA attention]: With self-attention, T and S are the same but for cross-attention they may be different. With vanilla Multi-Head Attention (MHA), N and K are the same while for Multi-Query Attention (MQA) K=1 and for Grouped MQA (GMQA) K merely has to divide N.
Global FLOPs and Params Calculation
For the below we’re going to compute per-layer FLOPs to avoid having to stick factors of L everywhere.
MLPs
The MLPs of a Transformer typically consist of 2 input matmuls that are element-wise combined and a single output matmul:
Attention
For the generic grouped-query attention case with different Q and KV head numbers, let us assume equal head dimension H for Q,K,V projections, and estimate the cost of the QKVO matmuls:
The dot-product attention operation is more subtle, effectively being a
Other Operations
There are several other operations happening in a Transformer. Layernorms are comparatively cheap and can be ignored for first-order cost estimates. There is also the final enormous (though not per-layer) unembedding matrix multiply.
General rule of thumb for Transformer FLOPs
If we neglect the cost of dot-product attention for shorter-context training, then the total FLOPs across all layers is
Leading to a famous rule of thumb for estimating dense Transformer FLOP count, ignoring the attention FLOPs. (Unembedding is another simple matmul with 6BSDV FLOPs and DV params, and follows the same rule of thumb.)
Fractional cost of attention with context length
If we do account for dot-product attention above and assume
So the takeaway is that dot-product attention FLOPs only become dominant during training once T>8D. For D ~ 8k, this would be ~64K tokens. This makes some sense, since it means as the MLP size increases, the attention FLOPs become less critical. For large models, the quadratic cost of attention is not actually a huge obstacle to longer context training. However, for smaller models, even e.g. Gemma-27B, D=4608 which means attention becomes dominant around 32k sequence lengths. Flash Attention also helps alleviate the cost of long-context, which we discuss briefly in Appendix A.
Miscellaneous Math
Sparsity and Mixture-of-Experts
We’d be remiss not to briefly discuss Mixture of Experts (MoE) models, which replace the single dense MLP blocks in a standard Transformer with a set of independent MLPs that can be dynamically routed between. To a first approximation, an MoE is just a normal dense model with E MLP blocks per layer, instead of just one. Each token activates k of these experts, typically k=2. This increases the parameter count by O(E), while multiplying the total number of activated parameters per token by k, compared with the dense version.
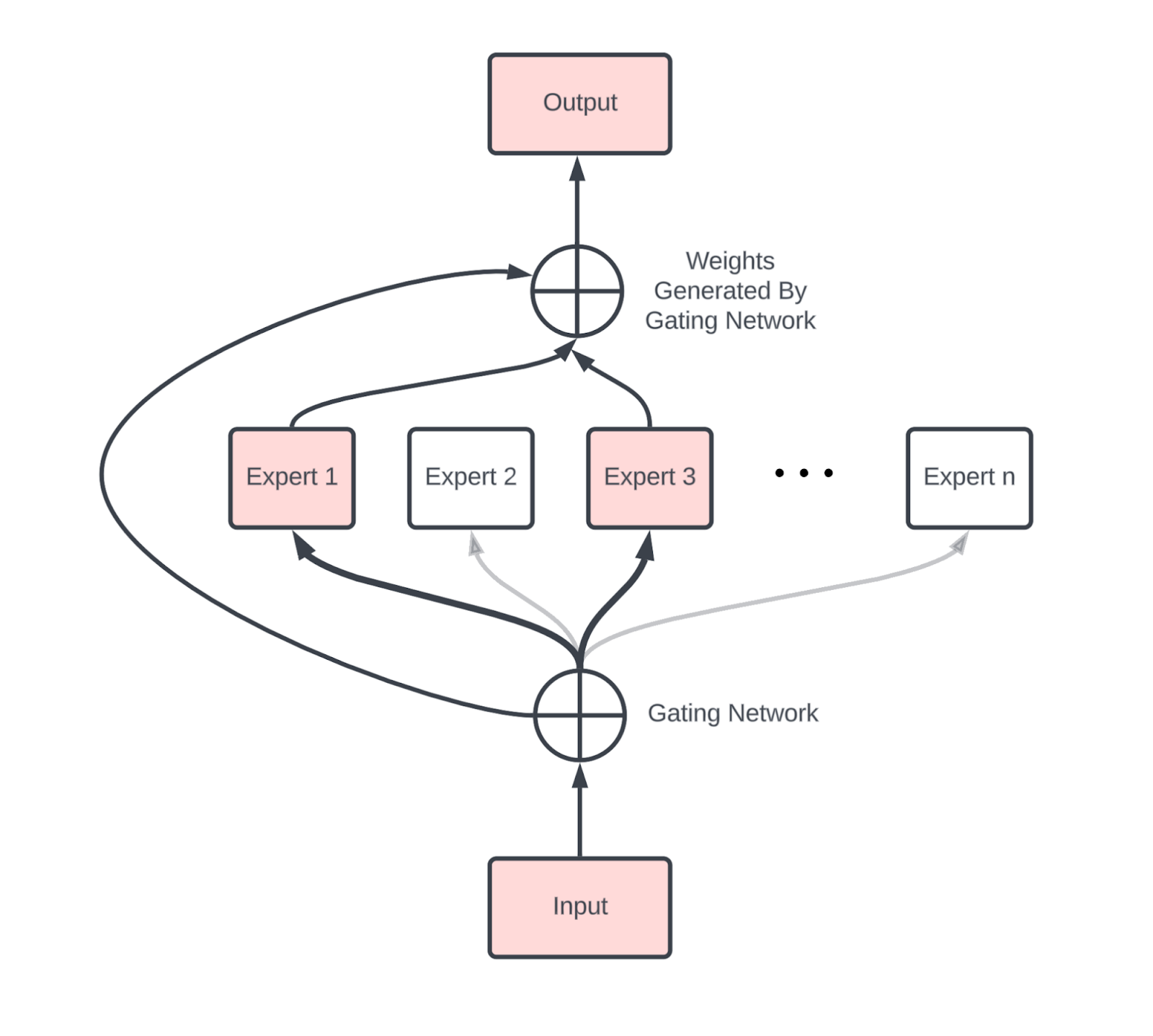
Figure: an example MoE layer with n experts. The gating expert routes each token to k of them, and the output of those MLPs get summed. Our parameter count is times the size of each expert, but only are used for each token. Source.
Compared to a dense model, an MoE introduces new comms, primarily two AllToAlls (one before and one after the MoE block) that route tokens to the correct expert and bring them back to their home device.Technically, this only happens if we are data or sequence sharded along the same axis as our experts. However as we saw in the previous section, the cost of each AllToAll is only 1/4 that of a comparable AllGather along a single axis (for a bidirectional ring).
Gradient checkpointing
Backpropagation as an algorithm trades memory for compute. Instead of a backward pass requiring
so to avoid recomputing we need to save
- Block remat: only save the input to each layer. This is the most aggressive method we use and only saves 1 checkpoint per layer, meaning we’d only save 4.2TB in the example above. This forces us to repeat essentially all forward pass FLOPs in the backward pass, meaning we increase our FLOPs from
to roughly . - Big matmuls only: another simple policy is to only save the outputs of large matmuls. This lets us avoid recomputing any large matmuls during the backward pass, but still makes us recompute other activation functions and parts of attention. This reduces 20 per layer to closer to 7 per layer.
This by no means comprehensive. When using JAX, these are typically controlled by jax.remat / jax.checkpoint (you can read more here).
Key-Value (KV) caching
As we’ll see in Section 7, LLM inference has two key parts, prefill and generation.
- Prefill processes a long prompt and saves its attention activations in a Key-Value Cache (KV Cache) for use in generation, specifically the key-value projections in the attention block.
- Generation batches several of these KV caches together and samples tokens from each of them.
Each KV cache is then effectively an array of size [2, S, L, K, H] where the 2 accounts for the keys and values. This is quite large! The total size of the Key-Value cache in int8 is 2SLKH. For a moderately-sized model with 8k context length, 64 layers, and KH = NH = D = 8192, this is 2 \cdot 8192 \cdot 64 \cdot 8192 = 8\text{GiB}. You can see why we would want to use GMQA with K \ll N.
What Should You Take Away from this Section?
- The overall parameters and FLOPs of a Transformer are fairly easy to calculate, and are summarized here, assuming MHA (with batch size B, vocab size V, a sequence of length T, D=d model, and F=d ff):
| Component | Params per layer | Training FLOPs per layer |
|---|---|---|
| MLP | 3DF | 18BTDF |
| Attention | 4DNH | 24BTDNH + 12BT 2 NH |
| Other | D | BTD |
| Vocab | DV (total, not per-layer) | 12BTDV |
- The parameter count of the MLP block dominates the total parameter count and the MLP block also dominates the FLOPs budget as long as the sequence length T < 8D.
- The total FLOPs budget during training is well approximated by
for reasonable context lengths. - During inference, our KV caches are roughly
per cache, although architectural modifications can often reduce this.
A Few Problems to Work
Question 1: How many parameters does a model with D=4096, F=4 \cdot D, V=32,000, and L=64 have? What fraction of these are attention parameters? How large are our KV caches per token? You can assume N\cdot H=D and multi-head attention with int8 KVs.
Click here for the answer.
- The total parameters is roughly
. For the given numbers, this is , or 16B parameters. - The ratio of attention parameters to total parameters in general is
. This gives us roughly 1/4 of parameters are used in attention. - Per token, our KV caches are
in int8, which is 512kB / token.
Question 2: How many total FLOPs are required to perform A[B X, D Y] * D W[D Y, F] on {‘X': 4, ‘Y': 8, ‘Z': 4}. How many FLOPs are performed by each TPU?
Click here for the answer.
The total “theoretical” FLOPs of the operation is
Question 3: How many FLOPs are involved in performing A[I,J,K,L] * B[I,J,M,N,O] \rightarrow C[K,L,M,N,O]?
Click here for the answer.
Following the rule above, we have I and J as contracting dimensions and K, L, M, N, and O as non-contracting dimensions. We have no “batching dimensions”, so this is just
Question 4: What is the arithmetic intensity of self-attention (ignoring the Q/K/V/O projections)? Give the answer as a function of the Q and KV lengths T and S. At what context length is attention FLOPs-bound? Given the HBM bandwidth of our TPUs, plot the effective relative cost of attention to the FFW block as the context length grows.
Click here for the answer.
Self-attention requires loading the
So our total bytes is
So basically, during prefill we have
Question 5: At what sequence length are self-attention FLOPs equal to the QKVO projection FLOPs?
Click here for the answer.
This is purely a question of when
Question 6: Say we only save the output of each of the 7 main matmuls in a Transformer layer during our forward pass (Q, K, V, O + the three FFW matrices). How many extra FLOPs do we need to “rematerialize” during the backwards pass?
Question 7: DeepSeek v3 says it was trained for 2.79M H800 hours on 14.8T tokens (source). Given that it has 37B activated parameters, roughly what hardware utilization did they achieve? Hint: note that they used FP8 FLOPs without structured sparsity.
Click here for the answer.
From the spec sheet here, we find 3,026 TFLOPs/s of FP8 performance with sparsity, or typically half this (1.513e15 FLOPs/s) without sparsity. 2.79M H800 hours means 2.79e6 * 1.513e15 * 60 * 60 = 1.52e25 total FLOPs. Given the activated parameter count of 37B, this training run should have used about 6 * 37e9 * 14.8e12 = 3.3e24 FLOPs. That means the FLOPs utilization is about 3.3e24 / 1.52e25 = 21.7%.
Question 8: Mixture of Experts (MoE) models have E copies of a standard dense MLP block, and each token activates k of these experts. What batch size in tokens is required to be compute-bound for an MoE with weights in int8 on TPU v5e? For DeepSeek, which has 256 (routed) experts and k=8, what is this number?
Click here for the answer.
Because we have E copies of each expert, in int8, we need to load E \cdot D \cdot F bytes. Because each token activates k experts, we have 2\cdot k \cdot B \cdot D \cdot F FLOPs. To be compute-bound with bfloat16 FLOPs, we need an arithmetic intensity over 240 which happens when (2\cdot k \cdot BDF) / EDF > 240 or k \cdot B / E > 120.
Therefore, we need B > 120 \cdot E / k to be compute bound. For DeepSeek, this gives us B > 120 \cdot 256 / 8 = 3840. This is a remarkably large batch size at generation time.
The traditional objection to scaling Transformers to very long context is that the attention FLOPs and memory usage scale quadratically with context length. While it’s true that the attention QK product has shape [B, S, T, N] where B is the batch size, S and T are the Q and K sequence dims, and N is the number of heads, this claim comes with some serious caveats:
- As we noted in Section 4, even though this is quadratic, the attention FLOPs only dominated when
, and especially during training the memory of a single attention matrix is small compared to all of the weights and activation checkpoints living in memory, especially when sharded. - We don’t need to materialize the full attention matrix in order to compute attention! We can compute local sums and maxes and avoid ever materializing more than a small chunk of the array. While the total FLOPs is still quadratic, we drastically reduce memory pressure.
This second observation was first made by Rabe et al. 2021 and later in the Flash Attention paper (Dao et al. 2022). The basic idea is to compute the attention in chunks of K/V, where we compute the local softmax and some auxiliary statistics, then pass them onto the next chunk which combines them with its local chunk. Specifically, we compute
- M: The running max of
over the sequence dimension - O: The running full attention softmax over the sequence dimension
- L: The running denominator
With these, we can compute the new max, the new running sum, and the new output with only a constant amount of memory. To give a sketchy description of how this works, attention is roughly this operation:
The max is subtracted for numerical stability and can be added without affecting the outcome since
Then we can combine these into the full softmax sum for these two chunks together by using
where
This can be done for the full softmax as well, giving us a way of accumulating arbitrarily large softmax sums. Here’s the full algorithm from the Flash Attention paper.

From a hardware standpoint, this lets us fit our chunk of Q into VMEM (what the algorithm above calls on-chip SRAM) so we only have to load the KV chunks on each iteration, reducing the arithmetic intensity. We can also keep the running statistics in VMEM.
One last subtle point worth emphasizing is an attention softmax property that’s used to make the Flash VJP (reverse mode derivative) calculation practical for training. If we define an intermediate softmax array as:
In attention, we obtain dS from reverse-mode dO and V arrays:
During the backpropagation of this gradient to Q and K
We exploit an identity that allows us to exchange a contraction along the large key length dimension with a local contraction along the feature depth dimension.
This replacement is crucial for being able to implement a sequence-block local calculation for the VJP, and enables further clever sharding schemes like ring attention.
Footnotes
- Technically, this only happens if we are data or sequence sharded along the same axis as our experts.